Project Description
“Within The Context-Tree Weighting Project a universal data compression algorithm for the class of tree sources was developed that combines an excellent performance with a straightforward analysis. It received the IEEE Information Society Paper Award in 1996.”
Results and Publications
F. Willems, Y.M. Shtarkov and T.J. Tjalkens, “The context-tree weighting method: basic properties”, in IEEE Transactions on Information Theory, vol. 41, no. 3, pp. 653-664, May 1995.
F. Willems, Y.M. Shtarkov and T.J. Tjalkens, “Context weighting for general finite-context sources”, in IEEE Transactions on Information Theory, vol. 42, no. 5, pp. 1514-1520, Sep. 1996.
F. Willems, “The context-tree weighting method: extensions”, in IEEE Transactions on Information Theory, vol. 44, no. 2, pp. 792-798, Mar. 1998.
Partners
TU Eindhoven (TUE)

How it started
In May 1992 Dr. Yuri Shtarkov from the Institute for Problems of Information Transmission (Moscow) visited our group to do joint research in source coding. We (Tjalling, Yuri, and Frans) decided to take a close look at Rissanen’s Context algorithm and related concepts. Our first observation was that weighting was a better principle than making decisions. Playing around with some examples led to the above tree-recursive weighting formula. It comes from the first manuscript which was dated May 14. The formula says that the weighted probability u in node c is the average of the estimated probability q corresponding to node c and the product of the weighted probabilities of the children 0c and 1c of node c. The analysis of this weighting formula made us more enthusiastic every day. We decided to submit the result to the IEEE International Symposium on Information Theory which was to be held in San Antonio in January 1993.
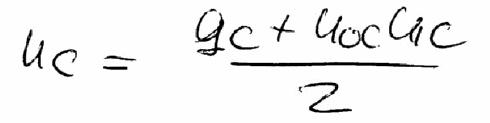
Best Paper Award of the Information Theory Society
For the paper “Context-Tree Weighting: Basic Properties” published in the May 1995 issue of the IEEE Transactions on Information Theory, Frans Willems, Yuri Shtarkov, and Tjalling Tjalkens received the 1996 Paper Award of the IEEE Information Theory Society.
Mini-Course
Michelle Effros, editor of the IEEE Information Theory Newsletter at that time, asked us to write a “Reflections on” -contribution. This article contains a mini-course on universal source coding and an introduction to the Context-Tree Weighting Method. The scanned version of this article is here together with some details about the computation of the weighted probabilities related to figure 6.
The Basic Algorithm
The basic principles of the context-tree weighting method are described in the paper “The Context-Tree Weighting Method : Basic Properties” by F.M.J. Willems, Y.M. Shtarkov, and Tj.J. Tjalkens which appeared in the 1995 May-issue of the IEEE Transactions on Information Theory, pp. 653-664.
Abstract: We describe a sequential universal data compression procedure for binary tree sources that performs the “double mixture”. Using a context tree, this method weights in an efficient recursive way the coding distributions corresponding to all bounded memory tree sources, and achieves a desirable coding distribution for tree sources with an unknown model and unknown parameters. Computational and storage complexity of the proposed procedure are both linear in the source sequence length. We derive a natural upper bound on the cumulative redundancy of our method for individual sequences. The three terms in this bound can be identified as coding, parameter and model redundancy. The bound holds for all source sequence lengths, not only for asymptotically large lengths. The analysis that leads to this bound is based on standard techniques and turns out to be extremely simple. Our upper bound on the redundancy shows that the proposed context tree weighting procedure is optimal in the sense that it achieves the Rissanen (1984) lower bound.
The Generalized Context Weighting Method
The context-tree weighting method was generalized to sources with structures (the mechanisms that select the parameters) that are more complex than tree structures. The generalized algorithms are again recursive, and they also achieve optimal redundancy behavior for sources in the model class for which the algorithm is designed. All this is discussed in the paper “Context Weighting for General Finite Context Sources,” by F.M.J. Willems, Y.M. Shtarkov and Tj.J. Tjalkens. This paper is published in the September 1996 issue of the IEEE Transactions on Information Theory, pp. 1514-1520.
Abstract: Context weighting procedures are presented for sources with models (structures) in four different classes. Although the procedures are designed for universal data compression purposes, their generality allows application in the area of classification.
Coding for Piecewise-Stationary Sources
Weighting techniques also can be applied for efficient coding of sequences generated by piecewise stationary sources. The transition pattern can be considered as (part of) the mechanism that selects the parameter(s) of the source, in other words as (part of) the model. For a binary memoryless source for which the parameter changes now and then, we could find two weigthing algorithms that achieve redundancies close to or even equal to the (Merhav-) lower bound that is known for this case. We have reported about these results in the paper “Coding for a Binary Independent Piecewise-Identically Distributed Source” by Frans M.J. Willems. This paper is published in the IEEE Transactions on Information Theory, vol. 42, pp. 2210-2217, November 1996.
Abstract: Two weighting procedures are presented for compaction of output sequences generated by binary independent sources whose unknown parameter may change occasionally. The resulting codes need no knowledge of the sequence length T, i.e they are strongly sequential, and also the number of parameter changes is unrestricted. The additional-transition redundancy of the first method was shown to achieve the Merhav [1993] lower bound, i.e. log(T) bit per transition. For the second method we could prove that additional-transition redundancy is not more than (3/2)log(T) bit per transition, which is more than the Merhav bound, however the storage and computational complexity of this method are also more interesting than those of the first method. Simulations show that the difference in redundancy performance between the two methods is negligible.
Text-Compression with the Context-Tree Weighting Method
Although the CTW-method is a binary technique, or was at least presented as a method for compressing binary source sequences, it is very well possible to apply this method to compress ASCII- or Byte-files. The ideas that make this possible, i.e., binary decomposition, zero-redundancy estimator, and weighting only at symbol-boundaries, are presented at the Data Compression Conference, March 25-27, 1997, Snowbird, Utah. These ideas make it possible to compress e.g. the “book2”-file in the Calgary Corpus downto 1.875 bit/ASCII, see DCC-1997 contribution “A Context-Tree Weighting Method for Text-Generating Sources,” by Tj.J. Tjalkens, P.A.J. Volf, and F.M.J. Willems. For more results on text-compression, please check the publications of former PhD student Paul Volf and his PhD thesis Weighting Techniques in Data Compression: Theory and Algorithms, TU Eindhoven, 2002.
More CTW Papers
F.M.J. Willems, Y.M. Shtarkov, and Tj.J. Tjalkens, “Context Weighting: General Finite Context Sources”, 14th Symposium on Information Theory in the Benelux, Veldhoven, The Netherlands, May 17 - 18, 1993, pp. 120 - 127.
Tj.J. Tjalkens, Y.M. Shtarkov, and F.M.J. Willems, “Context Tree Weighting: Multi-alphabet Sources,” 14th Symposium on Information Theory in the Benelux, Veldhoven, The Netherlands, May 17 - 18, 1993, pp. 128 - 135.
Tj.J. Tjalkens, Y.M. Shtarkov, and F.M.J. Willems, “Sequential Weighting Algorithms for Multi-Alphabet Sources,” 6th Joint Swedish-Russian International Workshop on Information Theory, Molle, Sweden, August 22 - 27, 1993, pp. 230 - 234.
F.M.J. Willems, Y.M. Shtarkov, and Tj.J. Tjalkens, “Context Tree Weighting: Redundancy Bounds and Optimality,” 6th Joint Swedish-Russian International Workshop on Information Theory, Molle, Sweden, August 22 - 27, 1993, pp. 235-239.
P.A.J. Volf and F.M.J. Willems, “Context Maximizing : Finding MDL Decision Trees,” 15th Symposium on Information Theory in the Benelux, Louvain-la-Neuve, Belgium, May 30 - 31, 1994, pp. 192 - 199.
Tj.J. Tjalkens, F.M.J. Willems, and Y.M. Shtarkov, “Multi-Alphabet Universal Coding Using a Binary Decomposition Context Tree Weighting Algorithm,” 15th Symposium on Information Theory in the Benelux, Louvain-la-Neuve, Belgium, May 30 - 31, 1994, pp. 259 - 265.
P.A.J. Volf and F.M.J. Willems, “A Study of the Context Tree Maximizing Method,” 16th Symposium on Information Theory in the Benelux, Nieuwerkerk a/d IJssel, The Netherlands, May 18 & 19, 1995, pp. 3 - 9.
F.M.J. Willems, “Weighting Algorithms,” IEEE Information Theory Workshop, Rydzina, Poland, June 25 - 29, 1995, pp. 7.3.1 -7.3.2.
P.A.J. Volf and F.M.J. Willems, “On the Context Tree Maximizing Algorithm,” IEEE International Symposium on Information Theory 1995, Whistler, BC, Canada, Sept. 17 - 22, p. 20.
P.A.J. Volf and F.M.J. Willems,“Context-Tree Weighting for Extended Tree Sources,” 17th Symposium on Information Theory in the Benelux, Enschede, The Netherlands, May 30 & 31, 1996, pp. 95 - 101.
F.M.J. Willems, “Implementing the Context-Tree Weighting Method,” ITW 1996, Haifa, Israel.
F.M.J. Willems and Tj.J. Tjalkens, “Complexity Reduction of the Context-Tree Weighting Method,” 18th Benelux Symposium on Information Theory,” May 15 & 16, 1997, in Veldhoven, The Netherlands. pp. 123 - 130.
P.A.J. Volf and F.M.J. Willems, “A Context-Tree Branch-Weighting Algoritm,” 18th Symposium on Information Theory in the Benelux, Veldhoven, The Netherlands, May 15 & 16, 1997, pp. 115 - 122.
P.A.J. Volf, “Context-tree Weighting for Text-Sources,” IEEE International Symposium on Information Theory 1997, Ulm, Germany, June 29 - July 4, p. 64.
F. Willems and M. Krom, “Live-and-Die Coding for Binary Piecewise I.I.D. Sources,” ISIT 1997, Ulm, Germany, June 29 - July 4, 1997.
Tj.J. Tjalkens and F.M.J. Willems, “Implementing the Context-Tree Weighting Method: Arithmetic Coding,” International Conference on Combinatorics, Information Theory & Statistics,” July 18-20, 1997, in Portland, Maine.
Tj.J. Tjalkens and F.M.J. Willems, “Complexity Reduction of the Context-Tree Weighting Method: A Study for KPN,” EIDMA-RS.97.01, Euler Institute of Discrete Mathematics and its Applications, 1997.
F.M.J. Willems, “Random Sequence Generation Using the Context-Tree Weighting Method,” ITW 1998, San Diego, California, February 8 - 11, 1998.
P.A.J. Volf and F.M.J. Willems, “The Switching Method: Elaborations,” 19th Symposium on Information Theory in the Benelux, May 28 - 29, 1998, pp. 13 - 20.
P.A.J. Volf, and F.M.J. Willems, “Switching Between Two Universal Source Coding Algorithms,” Data Compression Conference, Snowbird, Utah, March 30 - April 1, 1998, pp. 491 - 500.
J. Aberg, P. Volf, and F. Willems, “Compressing an Incompressible Sequence,” IEEE International Symposium on Information Theory 1998, Cambridge, Massachusetts, August 16 - August 21, 1998, p. 134.
F.M.J. Willems and Tj,J, Tjalkens, “Reducing the complexity of the context-tree weighting method,” IEEE International Symposium on Information Theory 1998, Cambridge, Massachusetts, August 16 - August 21, 1998.
F.M.J. Willems, Tj.J. Tjalkens, and P.A.J. Volf, “On Random-Access Data Compaction,” Rudy Ahlswede 60, Bielefeld, Germany, 199x. Also one-page summary at IEEE ITW 1999, Kruger Park, South Africa, June 20 - 25, 1999.
P.A.J. Volf, F.M.J. Willems, and Tj.J. Tjalkens, “Complexity-reducing techniques for the CTW algorithm,” Benelux Symposium, 1999.
Frans Willems, “Some Challenges in Source Coding,” ITG 2000, Munich, Germany, January 2000.
F.M.J. Willems, Y.M. Shtarkov, Tj.J. Tjalkens, “Context Tree Maximizing,” 2000 Conference on Information Sciences and Systems, Princeton University, March 15-17, 2000. (In fact this was the second part of the CTW manuscript that was submitted in 1993. The first part was published in 1995.)
A. Nowbakht, Tj.J. Tjalkens, and F.M.J. Willems, “Coding for Sources Satisfying a Permutation Property,” 22nd Symposium on Information Theory in the Benelux, May 15 - 16, Enschede, The Netherlands, 2001, pp. 77 - 84.
M.L.A. Stassen and Tj.J. Tjalkens, “A Parallel Implementation of the CTW Compression Algorithm,” Proc. 22nd Symposium on Information Theory in the Benelux, May 15 - 16, Enschede, The Netherlands, 2001, pp. 85 - 92.
F.M.J. Willems and P.A.J. Volf, “Reducing Model Cost by Weighted Symbol Decomposition,” ISIT 2001, Washington DC, June 24 - 29, 2001.
F.M.J. Willems, A. Nowbahkt-Irani, and P.A.J. Volf, “Maximum a-Posteriori Tree Models,” ITG 2002, Berlin, Germany, February, 2002.
A. Nowbakht and F.M.J. Willems, “Faster Universal Modeling for Two Source Classes,” Proc. 23nd Symposium on Information Theory in the Benelux, May 29 - 31, 2002, Louvain-la-Neuve, Belgium, pp. 29 - 36.
F.M.J. Willems, Tj.J. Tjalkens, and T. Ignatenko, “Context-Tree Weighting and Maximizing: Processing Betas,” Inaugural Workshop ITA (Information Theory and its Applications), UCSD Campus, La Jolla, Febr. 6 - 10, 2006.
T. Ignatenko, G.-J. Schrijen, B. Skoric, P. Tuyls, and F. Willems, “Estimating the Secrecy Rate of Physical Unclonable Functions with the Context-Tree Weighting Method,” IEEE ISIT 2006, Seattle, WA, July 9-14, 2006.
F.M.J. Willems, “Using a Universal Coding Technique for Sources with Large Alphabets to Estimate Differential Entropy,” 44th Annual Allerton Conference on Communication Computing and Control, Monticello, USA, Sept 27-29, 2006.